Self-supervised learning (SSL) has emerged as the de facto training paradigm for large models, where pre-training is followed by supervised fine-tuning using domain-specific data and labels. Despite achieving comparable performance to supervised methods, comprehensive efforts to assess SSL's impact on machine learning fairness (i.e., performing equally across different demographic groups) are lacking. With the hypothesis that SSL models would learn more generic, and hence less biased representations, this work explores the impact of pre-training and fine-tuning strategies on fairness.
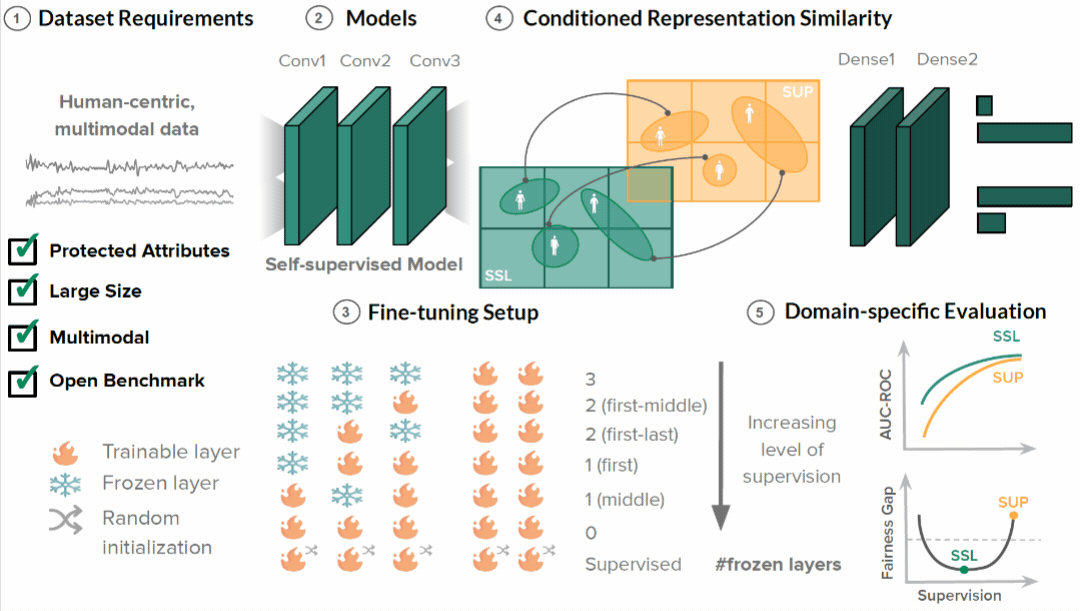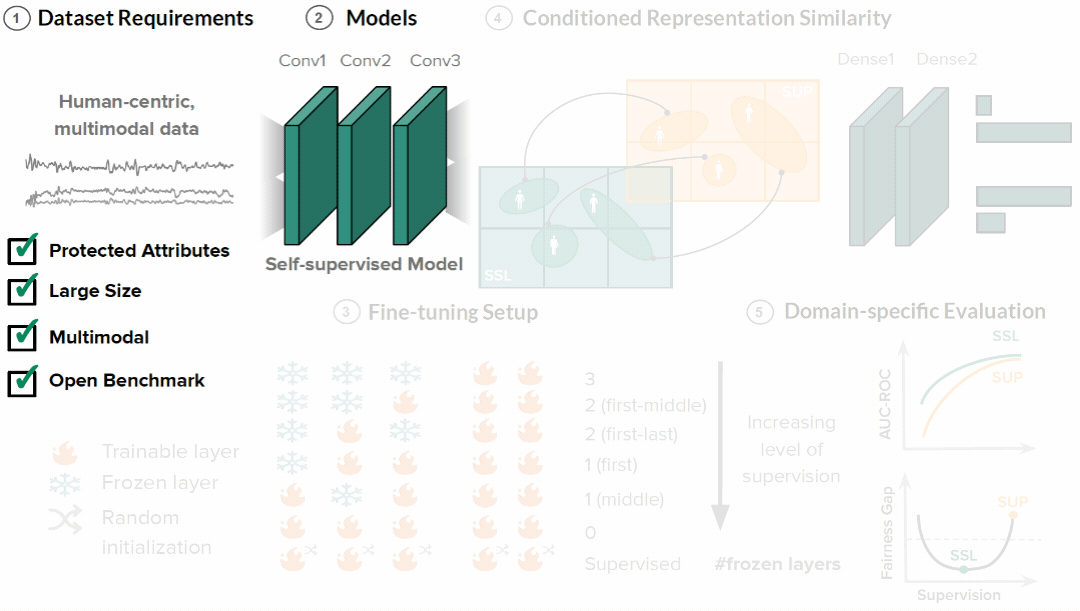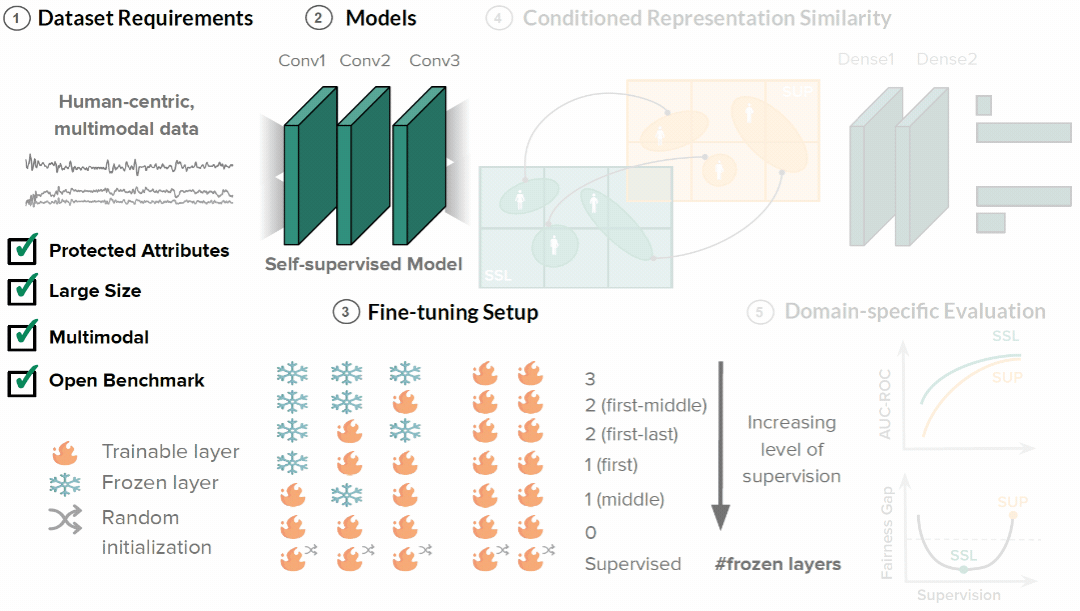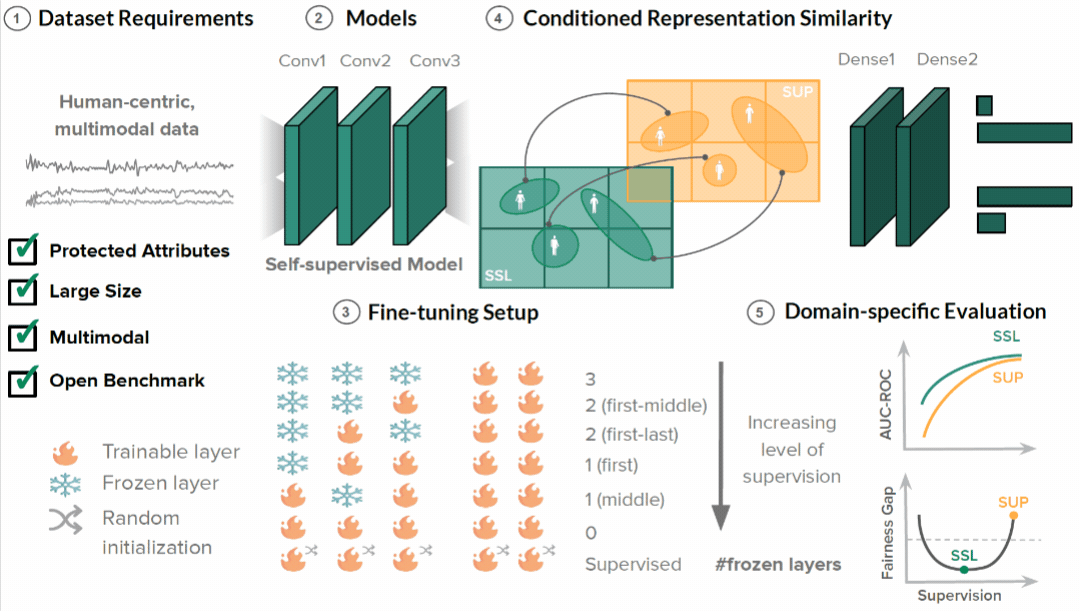
We introduce a fairness assessment framework for SSL, comprising five stages: defining dataset requirements, pre-training, fine-tuning with gradual unfreezing, assessing representation similarity conditioned on demographics, and establishing domain-specific evaluation processes. To evaluate our method's generalizability, we systematically compare hundreds of SSL and fine-tuned models across various dimensions, spanning from intermediate representations to appropriate evaluation metrics, on three real-world human-centric datasets (MIMIC, MESA, and GLOBEM).
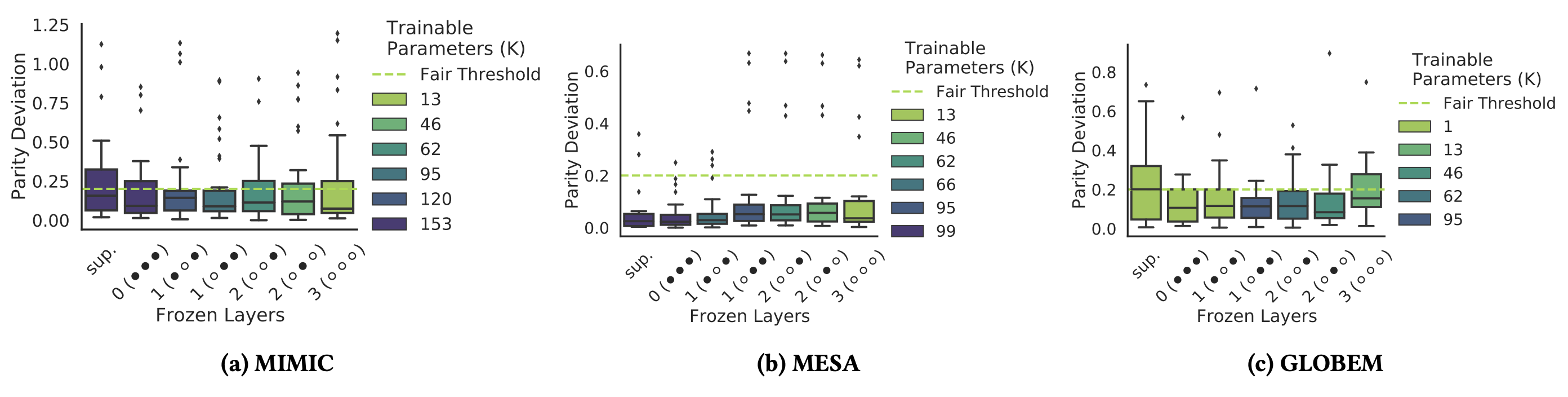
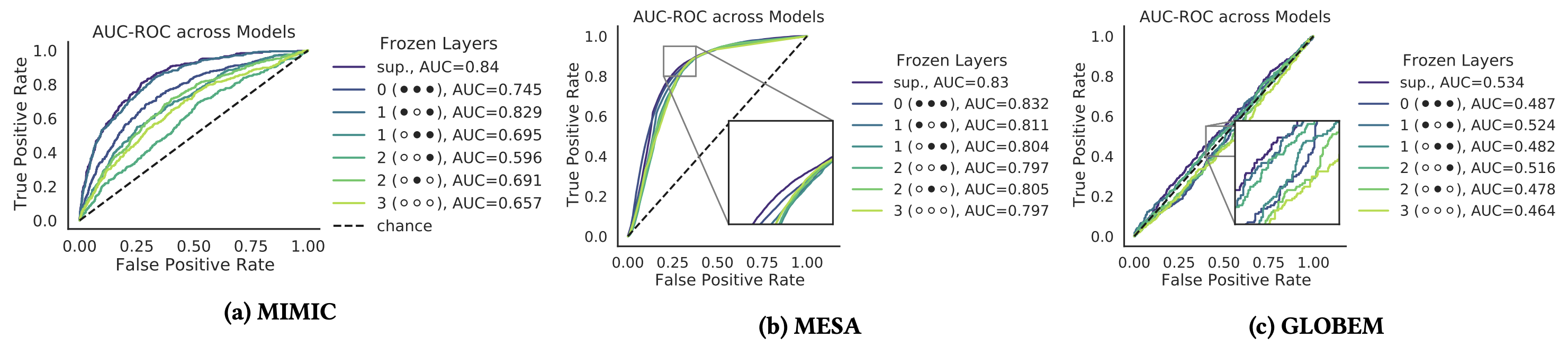
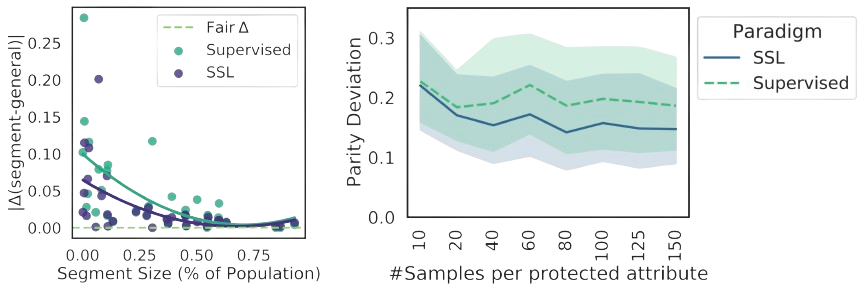
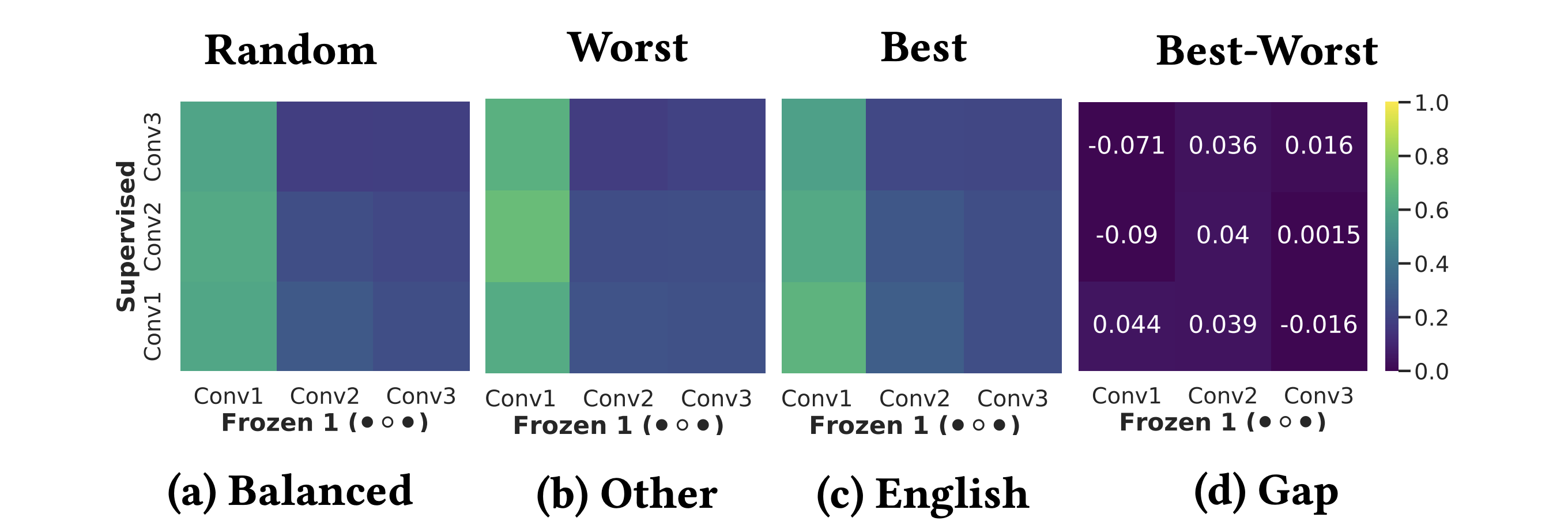
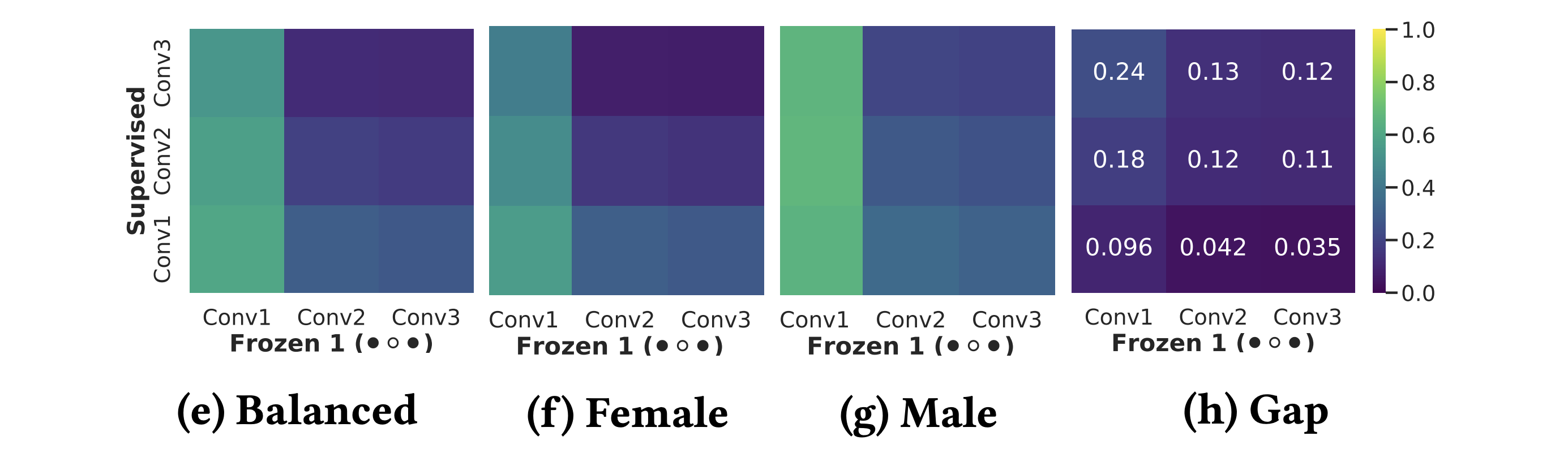
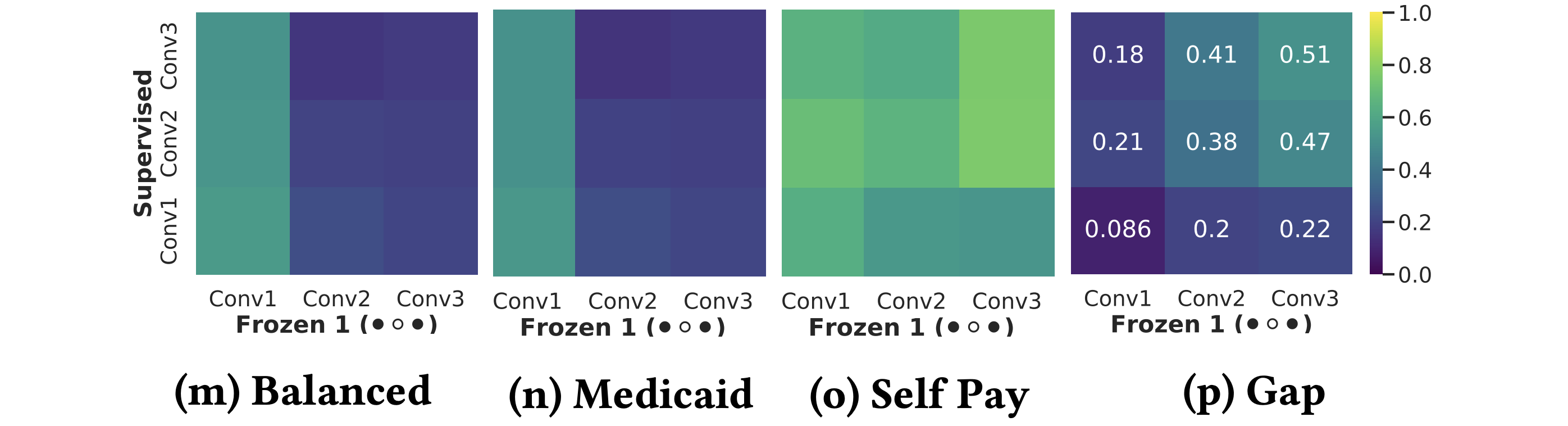
Our findings demonstrate that SSL can significantly improve model fairness, while maintaining performance on par with supervised methods, exhibiting up to a 30% increase in fairness with minimal loss in performance through self-supervision. We posit that such differences can be attributed to representation dissimilarities found between the best- and the worst-performing demographics across models - up to 13 times greater for protected attributes with larger performance discrepancies between segments.

{kind=link}